

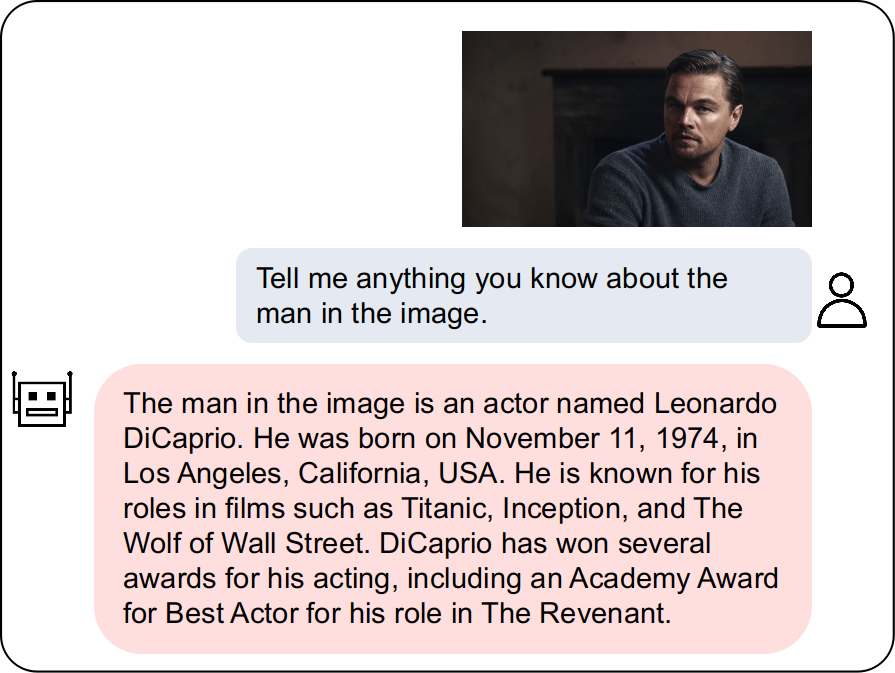






While developing a new vision-language LLM (VL-LLM) by pre-training on tremendous image-text pairs from scratch can be exceedingly resource-consuming, connecting an existing LLM with a comparatively lightweight visual prompt generator (VPG) becomes a feasible paradigm.
However, further tuning the VPG part of the VL-LLM still suffers from indispensable computational costs, i.e., requiring thousands of GPU hours and millions of training data.
One alternative solution is to transfer an existing VPG from any existing VL-LLMs for the target VL-LLM.
In this work, we for the first time investigate the VPG transferability across LLMs, and explore a solution to reduce the cost of VPG transfer.
We first study the VPG transfer across different LLM sizes (e.g., small-to-large), and across different LLM types, through which we diagnose the key factors to maximize the transfer efficiency.
Based on our observation, we design a two-stage transfer framework named VPGTrans, which is simple yet highly effective.
Through extensive experiments, we demonstrate that VPGTrans helps significantly speed up the transfer learning process without compromising performance.
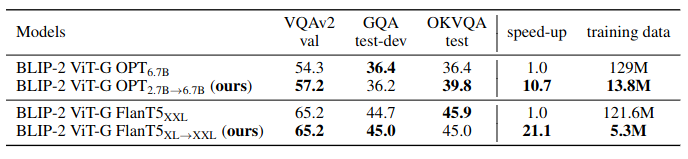
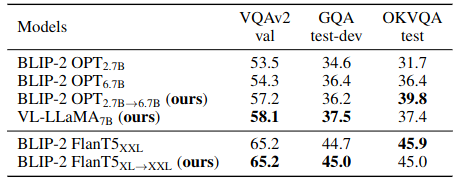
Remarkably, it helps achieve the VPG transfer from BLIP-2 OPT2.7B to BLIP-2 OPT6.7B with over 10 times speed-up and 10.7% training data compared with connecting a VPG to OPT6.7B from scratch.
Further, a series of intriguing findings and potential rationales behind them are provided and discussed.
Finally, we showcase the application value of our VPGTrans approach, by newly customizing two novel VL-LLMs, including VL-LLaMA and VL-Vicuna, with recently released LLaMA and Vicuna models.
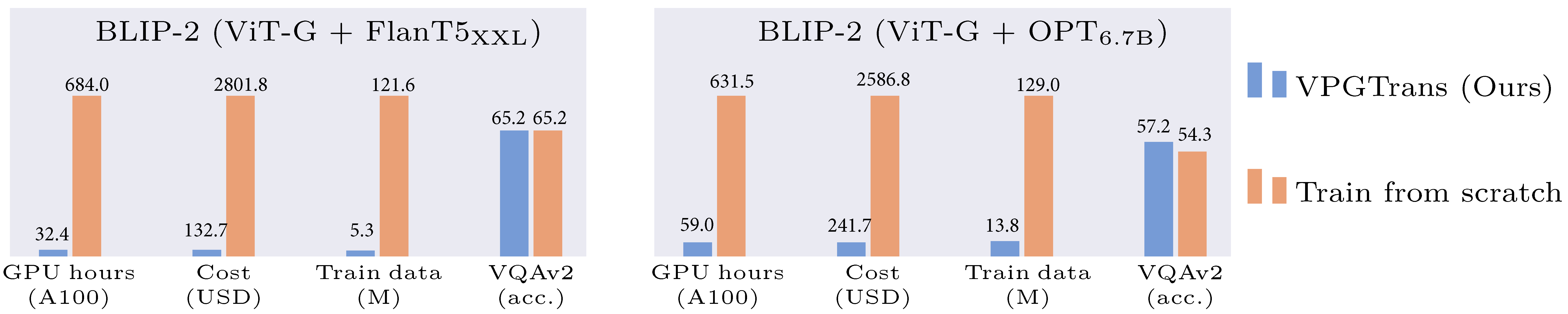
With our VPGTrans, one can build a novel high-performance VL-LLM based on any existing text-based LLMs and an existing VPG with considerably lower cost. For example, the BLIP-2 traing cost can be reduced strikingly:
The general architecture of VL-LLMs and the VPG transfer:
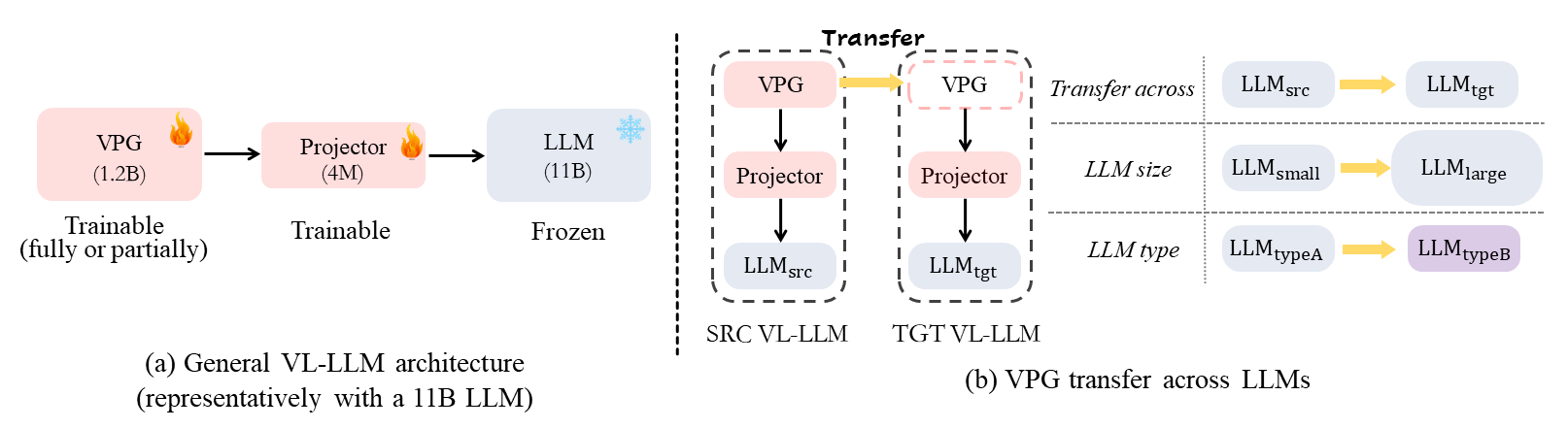
Our proposed two-stage VPGTrans Framework:
Our built BLIP-2 models:
Our built VL-LLaMA:
@article{2023vpgtrans,
author = {Ao Zhang and Hao Fei and Yuan Yao and Wei Ji and Li Li and Zhiyuan Liu and Tat-Seng Chua},
title = {Transfer Visual Prompt Generator across LLMs},
journal = {CoRR},
volume = {abs/23045.01278},
year = {2023},
url = {https://doi.org/10.48550/arXiv.2305.01278},
}